Introduction à la Cyber Threat Intelligence
Le concept de Cyber threat Intelligence (CTI) désigne la collecte et l'analyse d'informations sur les menaces et les risques en matière de cybersécurité. La CTI vise à fournir aux décideurs une vision globale des menaces et des risques en matière de cybersécurité.

Le concept de Cyber threat Intelligence (CTI) désigne la collecte et l'analyse d'informations sur les menaces et les risques en matière de cybersécurité. La CTI vise à fournir aux décideurs une vision globale des menaces et des risques en matière de cybersécurité.
Préambule
Le principe fondamental de renseignement existe depuis de nombreuses décennies.
Historiquement, la notion de renseignement était déjà employé pendant l'Antiquité et au Moyen Âge — aussi bien au sein du Moyen-Orient (Mésopotamie, Égypte, Perse...), qu'en Extrême-Orient (Chine, Inde...) et en Europe (Carthage, Rome, Grèce).

Il existe par ailleurs de très bons exemples historiques : dans l’Ancien Testament et la Bible ; dans les récits d’Hérodote et ceux des historiens romains ; pendant les Croisades (pratiqué tant par les royaumes Chrétiens que Musulmans) ; pendant la guerre de Cent Ans (caractérisée par une pratique constante de conspirations, d'intrigues et de manœuvres secrètes entre les belligérants, pratiquées par des espions, des traîtres et des agents...) ; dans la péninsule ibérique lors de la Reconquista ; au Japon avec les ninjas (contrairement à la croyance commune, probablement dû à la confusion qu'ont les individus quand il s'agit de différencier Samouraï et Ninja, ces derniers n'étaient pas soumis au Bushidō, et pratiquaient, souvent en omettant volontairement toutes valeurs ou éthiques, de nombreuses missions d'espionnage, d'infiltration, de sabotage, d'assassinat...) ; ou encore dans les deux plus anciens traités de stratégie au monde (L’Art de la Guerre de Sun Tse et l’Arthasastra de Kautilya)...
C'est à partir du 19e siècle que le terme de renseignement apparaît comme « information, plus ou moins difficile à obtenir, concernant l'ennemi », puis vers 1920 apparaît d'autres principes et expressions, à l'instar de celui de « service de recherche des renseignements » désignant les organismes étatiques consacrés à cette activité. Les services de renseignements avaient notamment pour mission de collecter, d'analyser et de traiter des informations afin de fournir aux pouvoirs publics un appui dans la prise de décision.
Depuis l'évolution et la prolifération des menaces Cyber (déstabilisation, espionnage, sabotage...) aux alentours des années 2000, une nouvelle notion est née et s'est particulièrement développé, celle d'intelligence du renseignement Cyber, justifiant la naissance de la notion de Cyber Threat Intelligence (CTI).
Le principe de la Cyber Threat Intelligence (CTI) et ses moyens
La CTI vise à collecter et à analyser les informations existant sur une menace ou un adversaire, notamment en dressant un portrait des attaquants ou en mettant en exergue des tendances (secteurs d'activités touchés, méthode utilisée, etc.), ce qui permettra de mieux identifier et analyser les cybermenaces.
La CTI inclut le « renseignement d'origine sources ouvertes (OSINT) », le renseignement à travers des sources privés (notamment sur des groupes Telegram, des sections privées de forums, des groupes Discord...), le renseignement humain et l'ingénierie sociale (Social Engineering), le renseignement technique, les fichiers journaux (logs), les données acquises « judiciairement » ou le renseignement sur le trafic Internet (à l'échelle du fournisseur) et les données dérivées du Dark Web.
Plus précisément, la CTI permet de définir les indicateurs d'attaque, les techniques utilisées, les groupes d'attaquants et les outils utilisés. Ce « profiling » permet de se défendre et anticiper au mieux les différents incidents, en permettant une détection aux prémices d'une attaque d'envergure (APT).
En effet, la CTI vise également à se préparer aux attaques en amont, en récupérant le plus d'informations possible sur ces attaquants. Couplé à cela, la mise en œuvre de mesures de prévention, de détection et de réponse par le biais des connaissances acquises.
Ces deux concepts (l'association de la collecte et la reconnaissance, avec la mise en place de mesures préventives de détection et de réponse) permettent d'obtenir une stratégie de CTI.
La CTI pourrait être résumée par le fait qu'elle vise à mieux connaître les menaces pour mieux se défendre et anticiper.
Les différents types de Cyber Threat Intelligence
Les différents types de Cyber Threat Intelligence sont essentiellement regroupés en quatre blocs.

- Tactique :
Le but est d'obtenir des renseignements sur les techniques d'attaque, cela rassemble tout ce qui est utilisé par les attaquants pour récupérer des informations et attaquer votre infrastructure, cela inclut notamment les méthodes utilisées par les attaquants, leurs habitudes et les outils dont ils se servent.
Les informations fournies ici seront principalement utilisées par le SOC Manager ou par l'intégrateur SIEM afin d'améliorer — d'affiner les méthodes de détection et mettre à jour vos infrastructures.
Ce sont des informations de bas niveau, dédiées à un usage sur le long terme.
- Technique :
L'objectif est de collecter des données sur les indicateurs de compromissions.
Prenons l'exemple d'un malware qui s'introduit dans un système. L'objectif du renseignement technique sera la collecte de renseignements connexes, en un sens, associés à la compromission, par exemple : quelle infrastructure de « Commande et Contrôle » (C&C ou C²) le malware a-t-il a contacté ? Quelle est là, ou quelles sont les signatures qui y sont associées ?
Le bloc technique ne doit pas être confondu avec le bloc tactique, puisque ce dernier se concentre davantage sur la compréhension de la vulnérabilité ayant été exploité. En effet, le bloc tactique se renseigne sur les méthodes et outils utilisées, alors qu'antithétiquement, le bloc technique se concentrera davantage sur les données et traces laissées permettant d'identifier le ou la personne — le ou les groupes à l'origine d'une attaque.
Ce bloc est souvent géré par le SOC — CSIRT (Computer Emergency Response Team), afin de permettre une meilleure identification des indicateurs de compromissions.
Ce sont des informations de bas niveau, dédiées à un usage sur le court terme.
- Opérationnelle :
L'objectif consiste à obtenir des informations sur les attaques futures.
Cela passe habituellement par des veilles sur Internet, sur les forums (de hacking), sur le Dark Web (commerces illégaux, forums), notamment à la recherche de leaks de credentials.
Il s'agit en quelque sorte d'OSINT, c'est-à-dire, en quelque sorte de produire du renseignement, permettant d'identifier les risques en amont.
Ce bloc est souvent géré par le RSSI ou le CERT (Computer Emergency Response Team), essentiellement pour permettre d'évaluer la capacité d'une organisation à se défendre contre de futures menaces.
Ce sont des informations de haut niveau, dédiées à un usage sur le court terme.
- Stratégique :
L'objectif consiste à obtenir de l'information sur les principales tendances actuelles, par exemple : quel groupe est particulièrement virulent ces derniers temps ? Quelles ont été les répercussions financières de l'attaque de la part de ce groupe pour les entreprises ? Divers renseignements au sujet des risques associés à un malware...
Ces renseignements seront principalement utilisés par l'exécutif (management) pour mesurer l'évolution de la menace et des risques, ce qui permettra de mieux prévoir les stratégies à adopter.
Ce sont des informations de haut niveau, dédiées à un usage sur le long terme.
Les indicateurs de compromissions
Un indicateur de compromission est une donnée qui permet de détecter une activité anormale et potentiellement malveillante sur un réseau ou un système. De nombreux indicateurs de compromissions se baladent dans la nature et peuvent se présenter sous de nombreuses formes, cela peut notamment inclure des éléments tels que des adresses IP, des noms de domaines, des règles YARA, des hashes (md5, sha1...) de fichiers, etc.
Compte tenu de l'abondance des informations, il est nécessaire en un premier temps de disposer d'une méthode correcte pour pouvoir les récupérer. Ensuite, plus important encore, il est nécessaire de disposer d'une méthode appropriée pour définir la manière de les gérer.
Trop d'information tue l'information. Par exemple, si on ne dispose pas des moyens nécessaires pour gérer, maintenir et exploiter une base de données de 10 millions d'indicateurs, aussi monumentale puisse-t-elle être, cette collecte n'a aucun intérêt.
C'est une erreur de vouloir récupérer trop d'indicateurs, pensant que cela apportera nécessairement une protection accrue. La chose la plus importante est d'être en mesure de recueillir intelligemment et de vous poser les bonnes questions.
Nous devons veiller à ce qu'il soit possible d'exploiter tous les indicateurs.
Votre EDR est-il capable de gérer des signatures SHA-1 ? Si tel est le cas, il pourrait être intéressant de récupérer de nombreuses signatures, sans quoi cela n'aurait quasiment aucune utilité.
Mieux gérer ses indicateurs de compromissions
Pour mieux gérer ses données (indicateurs), il faut également être capables de les classifier. La classification permet de regrouper des éléments qui présentent des caractéristiques similaires. Elle permet ainsi de mettre en valeur certains éléments par rapport à d’autres.
Voici quelques exemples d'éléments essentiels pour la classification de celles-ci.
- Le Scoring :
On distingue trois catégories de sources.
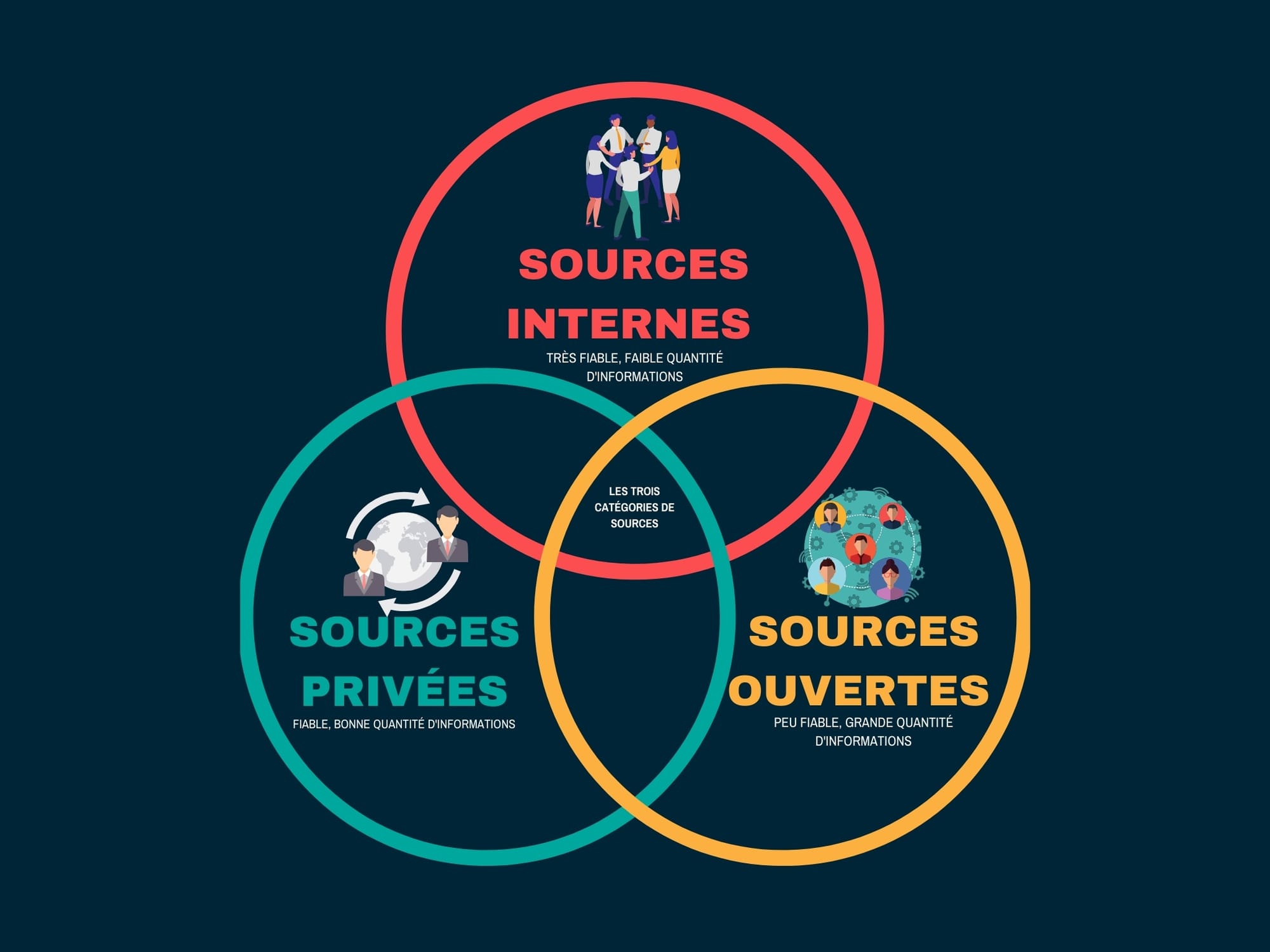
- Les sources ouvertes :
Ce sont des éléments récupérés sur Internet, provenant le plus souvent de sources telles que abuse.ch, AbuseIPDB, blocklist.de, VirusTotal... Mais également de données récupérées à la suite de veilles réalisées (Twitter, LinkedIn, forums et blogs sur Internet ainsi que sur le DarkWeb), ces derniers éléments peuvent être une véritable mine d'or.
- Les sources privées :
Il s'agit le plus souvent d'informations provenant des éditeurs de logiciels de CTI.
Le plus gros avantage réside dans le fait qu'il s'agit de données bien quantifiées et particulièrement fiables.
- Les sources internes :
Il s'agit des données récupérées en interne, par le biais de nos infrastructures.
Il s'agit de données obtenues en interne, par le biais de vos propres infrastructures et outils.
De toute évidence, ce sont les données les plus fiables de ces trois types. Si, à la suite d'une compromission de l'un de vos systèmes, vous avez été en mesure de récupérer une signature spécifique relatif à cette attaque, il n'y aura absolument aucun doute sur cet indicateur.
Chacun de ces types possède leurs avantages et leurs inconvénients. Typiquement, la source publique fournit beaucoup plus d'éléments, mais moins fiable que les autres types.
Il est nécessaire de mettre un système d'« échelle » (« scale ») en place.
Par exemple, je récupère les informations de sources ouvertes, mais ne les considère pas comme fiables dans un premier temps. Puis, après récupération d'une information provenant de ma source privée, si cette dernière entre en corrélation avec celle de ma source publique, cela fera un indicateur détecté par deux sources.
Une source peut être combinée à d'autres, ce qui peut aider à valider des éléments. Par exemple, une source primaire peut être combinée à une source secondaire pour valider un élément.
Je pourrais donc considérer mon indicateur comme fiable, et le placer au sein de mon SIEM (Security Information & Event Management).
- La durée de vie des indicateurs :
Il est nécessaire de ne pas garder éternellement les indicateurs dans une base, afin d'éviter la complexification de celle-ci.
De nombreux facteurs définissent la durée de vie des indicateurs (notamment la provenance de la source).
- Provenant d'une source ouverte : elle dépend de la source (notamment de sa fiabilité), mais elle correspond généralement à une durée de vie relativement courte.
- Provenant d'une source privée : elle dépend généralement des éditeurs de logiciels de CTI (elle est gérée automatiquement).
- Provenant d'une source interne : elle dépend beaucoup du type d'indicateur, typiquement, une signature pourrait facilement « évoluée » (être dépassée très rapidement), et il ne faut par conséquent donc pas trop se concentrer sur cette donnée dans un contexte moyen à long terme.
Une fois qu'une signature a déjà été enregistrée et détectée comme malicieuse par absolument tous les antivirus du marché, est-ce vraiment nécessaire de la conserver dans sa base. Antithétiquement, les adresses IP et noms de domaines sont des données bien plus pertinentes dans un contexte moyen à long terme, de par leurs plus grande complexité à « évoluée » (du moins, comparer à une simple signature). À titre de comparaison, une nouvelle signature est bien plus facile à obtenir qu'un nom de domaine ou une adresse IP.
- Le statut des indicateurs :
Il s'agit d'un facteur qui dépend en partie de la durée de vie des indicateurs.
- Le statut actif : ce sont des menaces actuelles.
- Le status whitelist (liste blanche) : pour l'anecdote, une entreprise a déjà subi le blocage d'un logiciel de communication tiers pendant de nombreuses heures au sein de toute l'infrastructure. Étant un logiciel utilisé régulièrement au sein de cette structure, les conséquences étaient désastreuses (relatif à la dépendance de l'entreprise à cet outil). À l'origine du blocage : une très vieille adresse IP qui avait été définis comme malveillante il y a de nombreuses années, mais avec le temps, celle-ci s'est retrouvée réattribué à des serveurs de la société éditrice du logiciel tiers en question. D'où l'importance de tenir à jour sa base, et bien gérer ses délais d'expiration.
- Le statut « à définir » : si l'indicateur n'est ni actif, ni sur liste blanche (whitelist), il est nécessaire de prendre le temps de vérifier et définir ces indicateurs.
- La confidentialité des indicateurs :
Ce facteur est déterminant. Il existe cinq niveaux de confidentialité, définis par le Traffic Light Protocol (TLP) - version 2.0.
Ce protocole de communication est utilisé pour échanger des informations sensibles entre les organisations, en associant des couleurs aux informations en fonction de leur niveau de sensibilité. Cela permet aux destinataires de prendre les mesures appropriées pour les protéger.
Le code couleur détermine dans quelle mesure les informations peuvent être partagées. Si une personne souhaite diffuser davantage les informations, elle doit obtenir le consentement de l’émetteur, sans initiative personnelle qui violerait le TLP.

- Les couleurs et leur signification :
- Le TLP Red : il s'agit du code le plus restrictif. Cela veut dire que l'information ne doit pas être divulguée, et est réservée aux participants (ou au service), sans possibilité de partage en dehors de ce groupe.
- Le TLP Amber : cela correspond à un niveau de divulgation limitée, restreinte à l'organisation, et ses clients sur une base de nécessité.
- Le TLP Amber+Strict : l’information est partagée exclusivement au sein de l’organisation, sans diffusion externe, même vers les clients et partenaires.
- Le TLP Green : l'information est réservée à un groupe, une communauté (ex. communauté cybersécurité), ou transversale entre entreprises partenaires uniquement, mais jamais via des canaux accessibles au public.
- Le TLP White : il s'agit du code le moins restrictif. Aucune restriction n'est imposée et l'information peut être divulguée librement, sous réserve des règles de droit d’auteur.
Conclusion
La CTI ne se limite pas à collecter des données brutes : elle transforme l'information en connaissance exploitable. Elle permet à l'organisation de ne plus être simplement réactive, mais stratégique, agile, et résiliente face à des menaces toujours plus furtives. Intégrer une démarche de CTI, c’est placer la compréhension des menaces au cœur de la cybersécurité.



